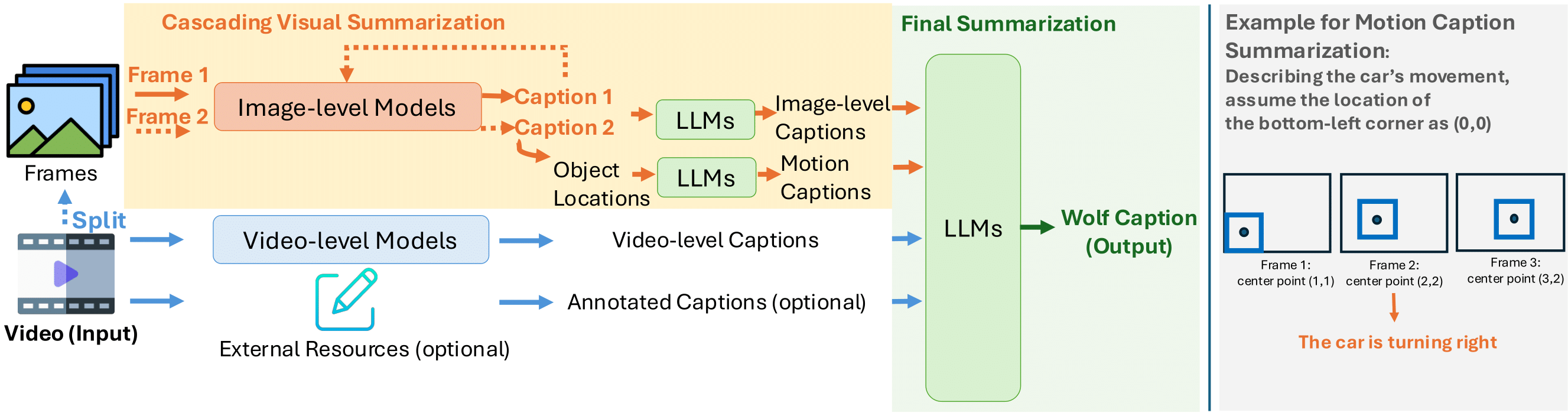
We propose Wolf, a WOrLd summarization Framework for accurate video captioning. Wolf is an automated
captioning framework that adopts a mixture-of-experts approach, leveraging complementary strengths of
Vision Language Models (VLMs). By utilizing both image and video models, our framework captures different
levels of information and summarizes them efficiently. Our approach can be applied to enhance video
understanding, auto-labeling, and captioning. To evaluate caption quality, we introduce CapScore, an
LLM-based metric to assess the similarity and quality of generated captions compared to the ground truth
captions. We further build four human-annotated datasets in three domains: autonomous driving, general
scenes, and robotics, to facilitate comprehensive comparisons. We show that Wolf achieves superior
captioning performance compared to state-of-the-art approaches from the research community (VILA1.5,
CogAgent) and commercial solutions (Gemini-Pro-1.5, GPT-4V). For instance, in comparison with GPT-4V, Wolf
improves CapScore (caption quality) by 55.6% and CapScore (caption similarity) by 77.4% on challenging
driving videos. Finally, we establish a benchmark for video captioning and introduce a leaderboard, aiming
to accelerate advancements in video understanding, captioning, and data alignment.